NC3 CTF 2022 2022
Rensdyrkartotek [200 pts]
Åh nej! Pillenissen ville lave lidt sjov med Flagmesternissens rensdyrkartotek. Han kom vist til at rode lidt for meget med databasen ved brug af besværgelsen databasus umuligius og nu beskyldes han af Flagmesternissen for at være roden til alt ondt denne jul. Uden rensdyrkartoteket kan Flagmesternissen ikke se hvilke rensdyr han skal spænde foran slæden for Julemanden. Samt Flagmesterkoden til slikskabet i rensdyrstalden havde han også deri. Kan du hjælpe Pillenissen med at løse hans rod?
NC3{Splitte_mit_sqlite_julerod_du_er_sej}
tl;dr
Filen er en sqlite3 fil, der er corrupted på forskellig vis. Først og fremmest erpage_size sat til 0, men bør være 4096.
Fikses dette, kan den parses og indholdet inspectes. Her gemmer sig bl.a. en encrypted ZIP-fil med flaget.Antal tabeller er sat til 6, men der ligger offsets til 7. Fikses dette, vil tabellen
metalnfo vises.
Denne består af 20 rækker, men rækken med ID 12 mangler og række 4 findes i stedet to gange. Dette kan igen fikses ved at opdatere et offset.
Tabellen har først kolonnen K0mb1 efterfulgt af kolonnerne 0-9.
Tallene i K0mb1 svarer til indices ind i rækken på tal, der skal concatenates.
Gøres dette for den manglende række 12 fås tallet 24122412241224122412, som er password til ZIP.
Introduktion
Vi får givet filen RensdyrKartotek.db, som ud fra beskrivelsen virker til at være en database, der er blevet corrupted.
Kører vi file, får vi ikke umiddelbart nogen hjælp:
$ file RensdyrKartotek.db
RensdyrKartotek.db: data
Vi tjekker også lige starten af filen ud:
$ xxd RensdyrKartotek.db | head
00000000: 5351 4c69 7465 2066 6f72 6d61 7420 3300 SQLite format 3.
00000010: 0000 0202 0040 2020 0000 0008 0000 0010 .....@ ........
00000020: 0000 0000 0000 0000 0000 000c 0000 0004 ................
00000030: 0000 0000 0000 0000 0000 0001 0000 0000 ................
00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000050: 0000 0000 0000 0000 0000 0000 0000 0008 ................
00000060: 002e 4f7d 0d00 0000 060a d900 0f54 0f02 ..O}.........T..
00000070: 0e49 0cf8 0b7f 0ad9 0c20 0000 0000 0000 .I....... ......
00000080: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000090: 0000 0000 0000 0000 0000 0000 0000 0000 ................
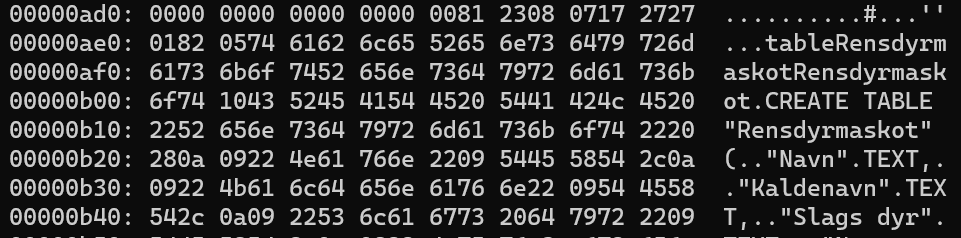
Her får vi noget mere info: Vi har at gøre med en SQLite 3 database-fil. strings kan give os en idé om nogle af tabellerne og dataen - vi ser f.eks. strings som
CREATE TABLE "Rensdyrmaskot" (
"Navn" TEXT,
"Kaldenavn" TEXT,
"Slags dyr" TEXT,
rende" INTEGER,
"Ansat af" TEXT
ktablePrim
CREATE TABLE "Rensdyr" (
gle" INTEGER,
"Rensdyrnavn" TEXT,
"Alder" INTEGER,
kkraft" INTEGER,
"Land" TEXT,
dedyr" INTEGER,
"Lederrolle" INTEGER,
"Favoritsnack" TEXT,
n" INTEGER,
"Selfie" BLOB,
"Selfiedato" INTEGER,
"Kendetegn" TEXT,
PRIMARY KEY("N
gle" AUTOINCREMENT)
NC3}XML: _{Billedformat Fejl}. 24{SQLite create table entry...}.25{Ikke underst
ttet format}.26{Rapporter til Flagmesternisse}.27{WAL parse}.28{Googles
gning:Hvor meget rod skal der til for at man beh
ver rodbehandling}
Lyn langs siden/
Tre striber/
Hjerteformet hale*
63Skumdelfin
En lille hov
og mange andre. Køres file carving tools som binwalk eller foremost kan vi også identificere og trække en række filer ud, primært billeder:
$ binwalk RensdyrKartotek.db
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 SQLite 3.x database,
17262 0x436E PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
17353 0x43C9 Zlib compressed data, compressed
18956 0x4A0C PNG image, 358 x 278, 8-bit/color RGB, non-interlaced
26015 0x659F JPEG image data, JFIF standard 1.01
28204 0x6E2C PNG image, 90 x 53, 8-bit/color RGB, non-interlaced
32366 0x7E6E PNG image, 87 x 55, 8-bit/color RGB, non-interlaced
34393 0x8659 JPEG image data, JFIF standard 1.01
34423 0x8677 TIFF image data, big-endian, offset of first image directory: 8
39979 0x9C2B Zip archive data, encrypted at least v2.0 to extract, compressed size: 53, uncompressed size: 41, name: Flagmesterkodeord.txt
40186 0x9CFA End of Zip archive, footer length: 22
40483 0x9E23 PNG image, 82 x 53, 8-bit/color RGB, non-interlaced
45211 0xB09B PNG image, 108 x 84, 8-bit/color RGBA, non-interlaced
45302 0xB0F6 Zlib compressed data, compressed
46518 0xB5B6 PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
46609 0xB611 Zlib compressed data, compressed
47628 0xBA0C PNG image, 358 x 278, 8-bit/color RGB, non-interlaced
47719 0xBA67 Zlib compressed data, compressed
49600 0xC1C0 PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
49691 0xC21B Zlib compressed data, compressed
50265 0xC459 PNG image, 108 x 84, 8-bit/color RGBA, non-interlaced
50356 0xC4B4 Zlib compressed data, compressed
51979 0xCB0B PNG image, 108 x 84, 8-bit/color RGBA, non-interlaced
52070 0xCB66 Zlib compressed data, compressed
54509 0xD4ED PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
54600 0xD548 Zlib compressed data, compressed
55165 0xD77D PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
55256 0xD7D8 Zlib compressed data, compressed
55827 0xDA13 PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
55918 0xDA6E Zlib compressed data, compressed
56720 0xDD90 PNG image, 108 x 84, 8-bit/color RGB, non-interlaced
56811 0xDDEB Zlib compressed data, compressed
Vi ser også en spændende ZIP-fil med filen Flagmesterkodeord.txt, men ZIP-filen er encrypted.
Billederne er primært af landeflag og nogle rensdyr, men det ville være noget mere brugbart at kunne parse filen med sqlite3 eller en DB viewer.
Analyse
Hvis vi skal kunne parse databasefilen, skal vi finde ud af, hvorfor den ikke identificeres korrekt af file og ikke læses rigtig ind af sqlite3. file kigger primært på headers og footers og tjekker magic bytes og evt. metadata. Det er derfor ikke usandsynligt, at noget er galt i starten af filen. For at tjekke det, må vi have fat i specifikationen: https://www.sqlite.org/fileformat.html.
Her finder vi følgende tabel for database headeren:
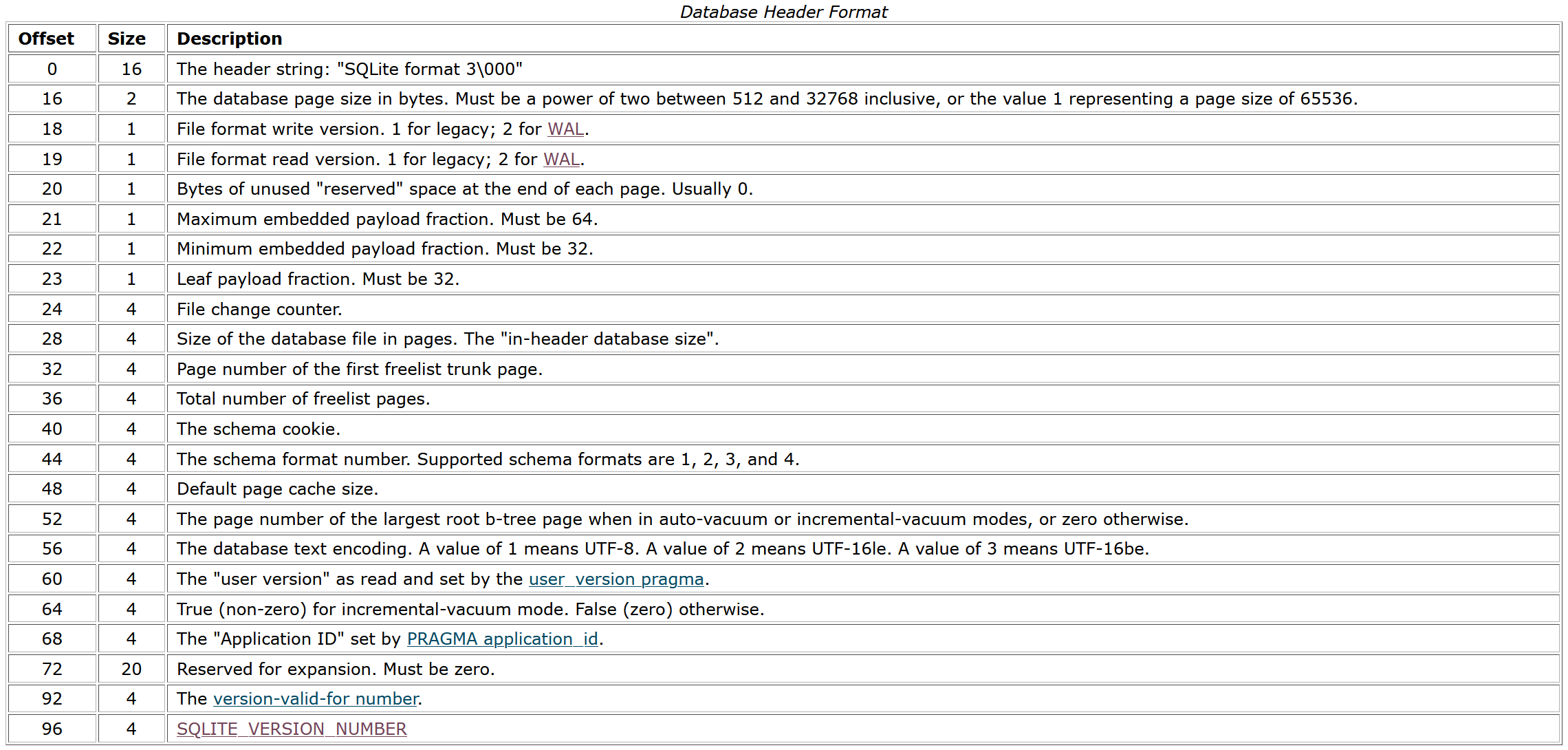
De første 16 bytes passer med den forventede header string. De næste to bytes indeholder database page size i bytes, men disse er begge null bytes i filen og vil helt sikker være en årsag til fejl. Det skal fikses, så vi tjekker først databasefilens størrelse:
$ wc RensdyrKartotek.db
217 4370 65536 RensdyrKartotek.db
Den er 65536 bytes, altså 0x10000 i hex. Størrelsen skal passe med page size gange antal pages, og vi ser i header tabellen, at antal pages er de fire bytes, der starter ved offset 28. Her har vi 00 00 00 10, så databasen har 16 pages:

Page size skal altså sættes til 0x10000 / 0x10 = 0x1000 (4096):

0Køres file igen nu, får vi helt andet output:
$ file RensdyrKartotek.db
RensdyrKartotek.db: SQLite 3.x database, last written using SQLite version 3035005, writer version 2,
read version 2, file counter 8, database pages 16, cookie 0xc, schema 4, UTF-8, version-valid-for 8
Filen kan nu åbnes i en DB viewer eller med sqlite3, og vi ser nu tydeligt tabellerne i databasen:
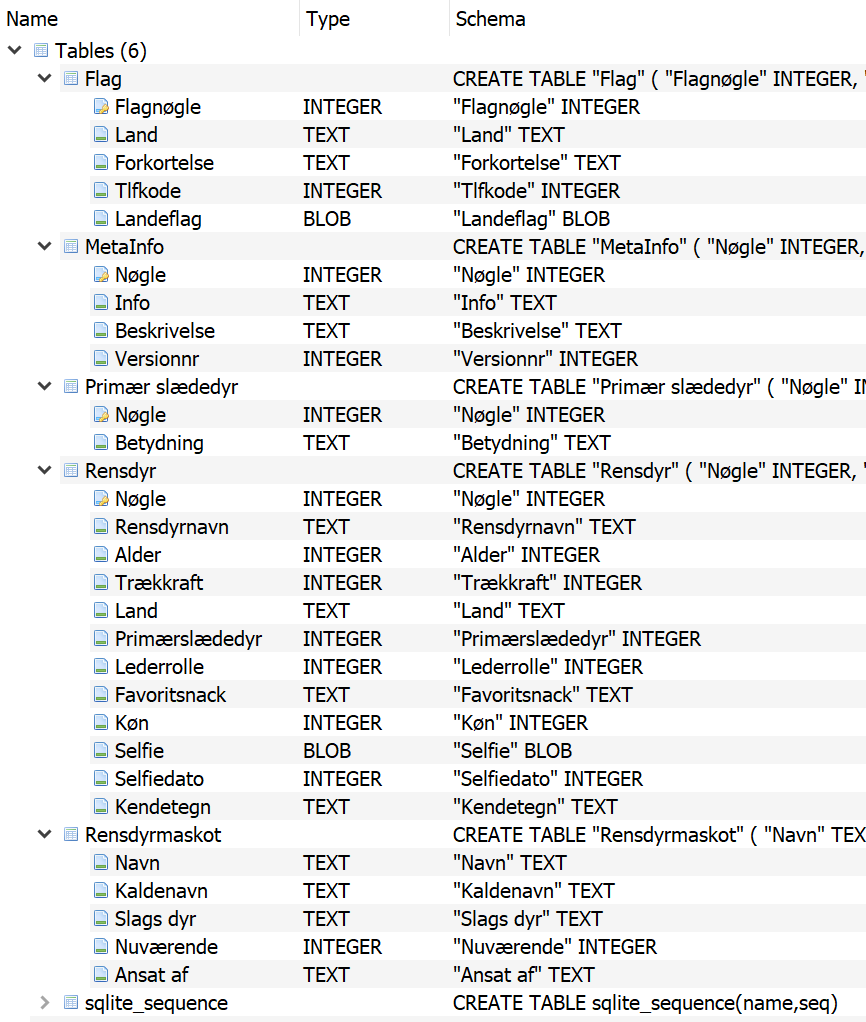
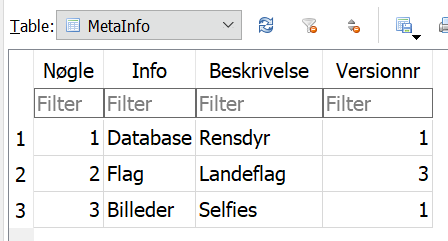
Vi inspicerer hver tabel for spændende indhold:
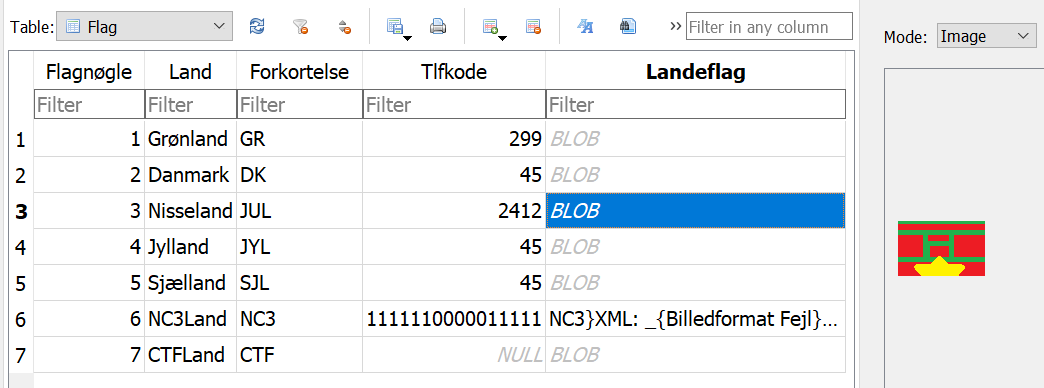
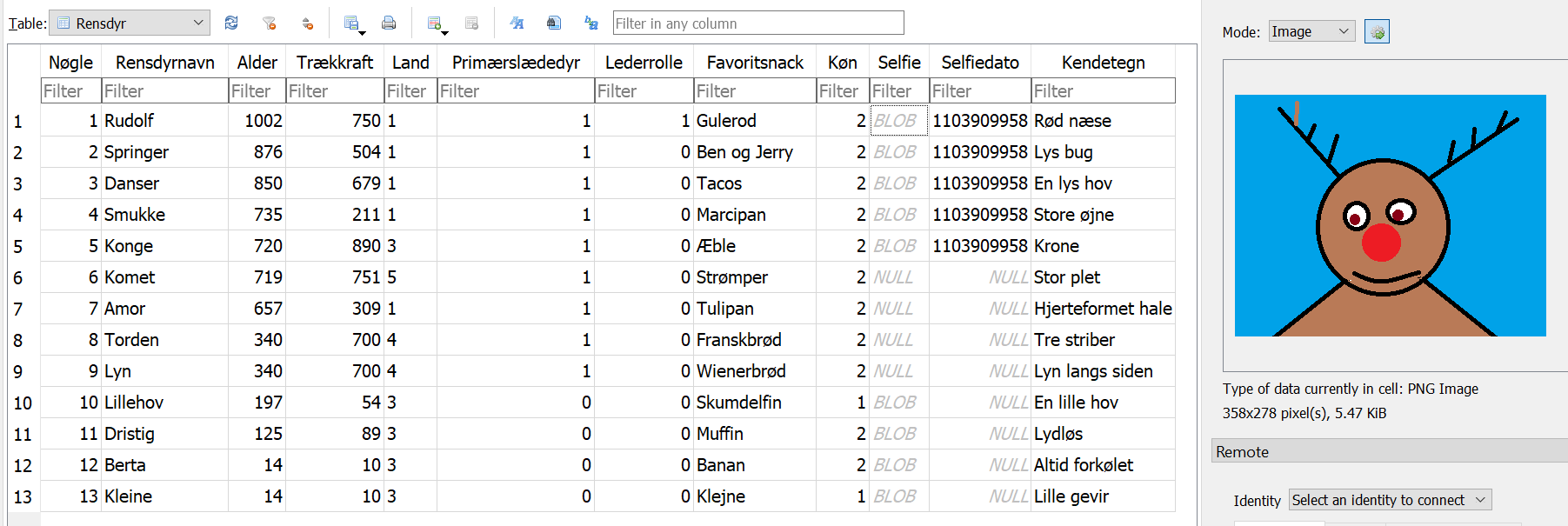
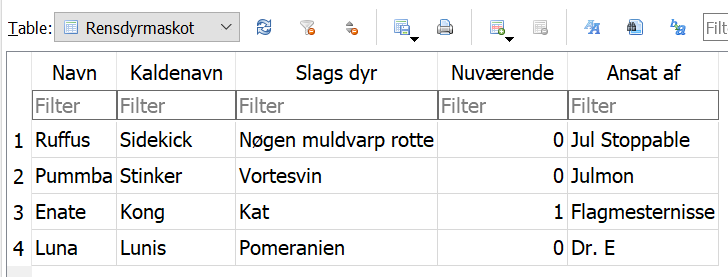
Tabellerne med flag, rensdyr og maskotter ser umiddelbart mest interessante ud. Flagtabellen indeholder primært rækker med forskellige flagbilleder i feltet Landeflag, men CTFLand har den encryptede ZIP-fil, vi også tidligere extractede, og NC3Land har følgende:
NC3}XML: _{Billedformat Fejl}. 24{SQLite create table entry...}.25{Ikke understøttet format}.26{Rapporter til Flagmesternisse}.27{WAL parse}.28{Googlesøgning:Hvor meget rod skal der til før at man behøver rodbehandling}
Rensdyr tabellen har lidt forskellig info om hvert rensdyr samt et selfie af nogle af dem. I tabellen Rensdyrmaskot virker den nuværende maskot mest relevant, ansat af Flagmesternisse, som også har den krypterede ZIP-fil. Dyret hedder Enate, kaldes Kong og er en Kat. Der er et lille hint her til senere, byttes navnene rundt får man KongKatEnate, altså concatenate.
Efter utallige timers gransken i tabellerne, de forskellige tal, navne, billeder (som hver kom igennem den store file carving + stego mølle), var det back to basics: Analyser filen ud fra filspecifikationen.
Umiddelbart efter database headeren ligger første B-Tree page:
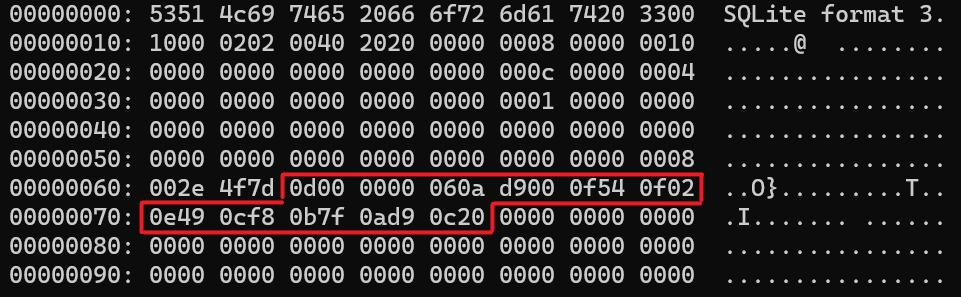
Vi går igen til specifikationen og finder en tabel for indholdet:

Første byte er 0x0d, så vi har at gøre med en “leaf table b-tree page”, hvis header vil være 8 bytes - de resterende er data. De næste to bytes er null bytes, så der er ingen freeblocks. Herefter har vi 00 06, som indikerer, at der er 6 data cells på pagen. Starten på cell content er de næste to bytes, 0a d9, dvs. cell content ligger på det offset inden i den nuværende page. Vi kan lige inspicere det offset, og her ser vi, at der faktisk starter noget content:
Umiddelbart er det selve tabeldefinitionerne der ligger her først, og de 6 data cells passer også med at vi så 6 tabeller i databasen.
Lige efter B-tree headeren vil cell pointer arrayet ligge, der indeholder offsets på de enkelte cells på pagen. Det er altså følgende:
0f54 0f02 0e49 0cf8 0b7f 0ad9 0c20
Her møder vi dog et problem - der er 7 table offsets, men der er kun blevet indikeret, der ville være 6 - vi mangler en tabel! Det kan hurtigt fikses, vi ændrer 00 06 til 00 07, så diverse parsers får den tabel med også. Åbner vi den opdaterede databasefil, får vi nu adgang til en før skjult tabel, metalnfo (endnu mere skjult, da titlen er tæt på metaInfo, der også lå):
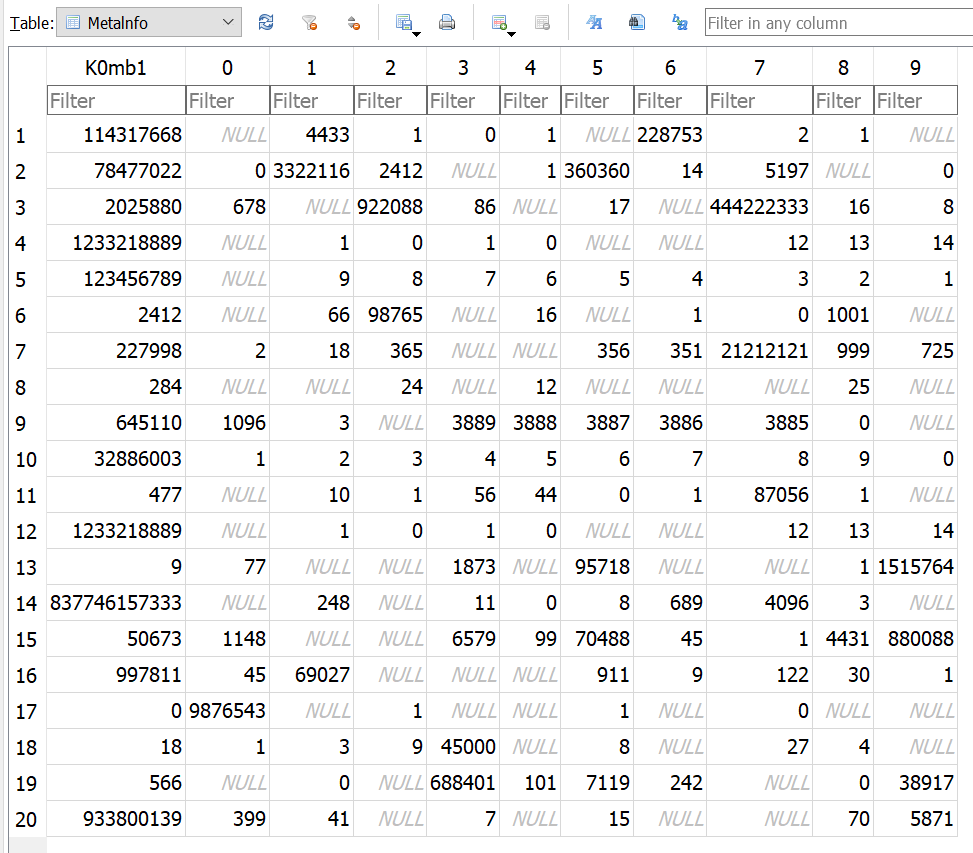
Denne tabel har en K0mb1 kolonne og herefter kolonner fra 0-9, og mange celler er NULL. Kombi tyder på, at cellerne i den første kolonne siger noget om, hvordan de resterende celler skal kombineres. Her brugte jeg først lang tid på, at se det som et ligningssystem med først en resultatvektor og så en koefficientmatrix, hvor NULL så var manglende koefficienter. Min idé var at få løst det system (hvordan det så end var bygget op), og at variabelværdierne så ville blive et 10-character password til ZIP-filen.
Efter mange sjove timer med det, gik det op for os, at der var sammenhæng i de tal, der stod i første kolonne, og de felter der ikke var NULL i resten. Det tydeligste eksempel er 284, hvor kun kolonne 2, 4 og 8 er udfyldt. Generelt gælder, at de cifre, der udgør tallet i første kolonne, svarer til celler, der ikke er NULL (der er også andre, der ikke er NULL, men kun ét eksempel på et ciffer, der svarer til en NULL-celle).
Nu var en sammenhæng fundet, og vi brugte igen mange timer på at forsøge at få mening ud af de potentielle resultater. En meget relevant observation var, at to af rækkerne er identiske. Rækker har også et rowid, og slår man den kolonne til, kan man se, at det faktisk ikke bare er to ens rækker, men den samme række, der ligger to gange - nemlig række 4:
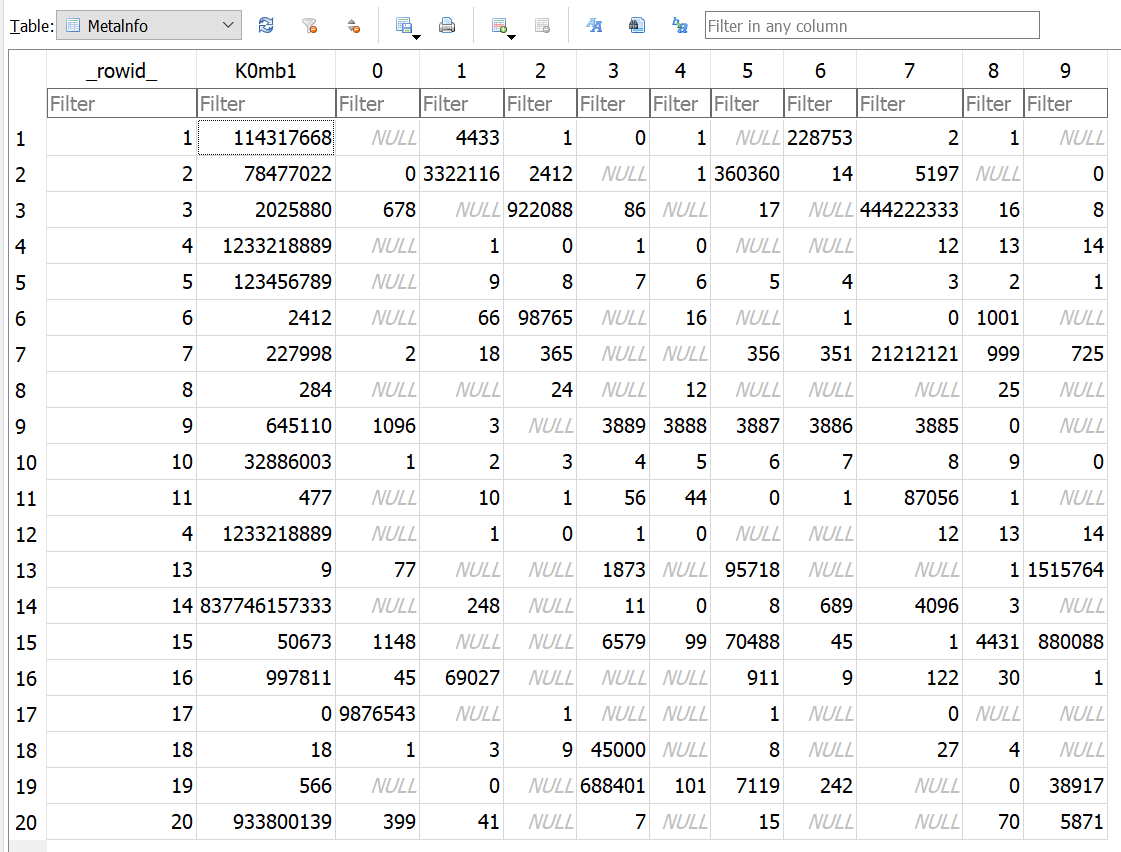
Til gengæld mangler på den position rækken med row id 12. Mon der er blevet rodet med dem også? Vi hopper tilbage i filen og finder indholdet af den tabel ved offset 0xa000:

Her har vi igen en B-tree leaf page og størrelsen er 0x14, altså 20 - passer med antal rækker. Vi har så følgende offsets:
0ed0 0eb3 0fe2 0fcd 0e99 0fb6 0e78 0e4b 0f86 0e5e
0f70 0fcd 0f58 0e10 0f39 0df6 0f27 0f10 0ddb 0ef6
Og vi ser som forventet at 4. og 12. offset er ens: 0x0fcd. Mon ikke der ligger en række med row id 12 ved et andet offset?
Jeg havde på nuværende tidspunkt skrevet lidt kode i Python til at parse alle records i en B-tree leaf page for at inspicere filen. Her kunne jeg indsætte et ekstra check for, om der lå data mellem de parsede records, hvilket gjorde det nemt at opdage den manglende record (koden er smidt ind i bunden til de interesserede):
RECORD 13 AT 0xe10
Length 27
Row ID 14
Columns: 11
Column data types:
0x5: int48 = 837746157333 (0x00c30d8fe715)
0x0: NULL
0x2: int16 = 248 (0x00f8)
0x0: NULL
0x1: int8 = 11 (0x0b)
0x8: 0
0x1: int8 = 8 (0x08)
0x2: int16 = 689 (0x02b1)
0x2: int16 = 4096 (0x1000)
0x1: int8 = 3 (0x03)
0x0: NULL
REMAINING AT 0xe2d:
1c 0c 0c 05 01 01 02 01 00 01 02 00 01 01 00
07 85 c7 db 04 04 11 01 9c 02 0c 15 ac 04 7a
Som det ses i bunden ligger der ekstra unparsed data ved offset 0xe2d, og denne data passer perfekt på en record. De starter med et length field og har dernæst row id, som vi ser her er 0x0c, altså 12 - den manglende række! Vi hopper tilbage til vores offset table og udskifter sidste 0fcd med 0e2d, og vi kan nu inspicere den manglende række:
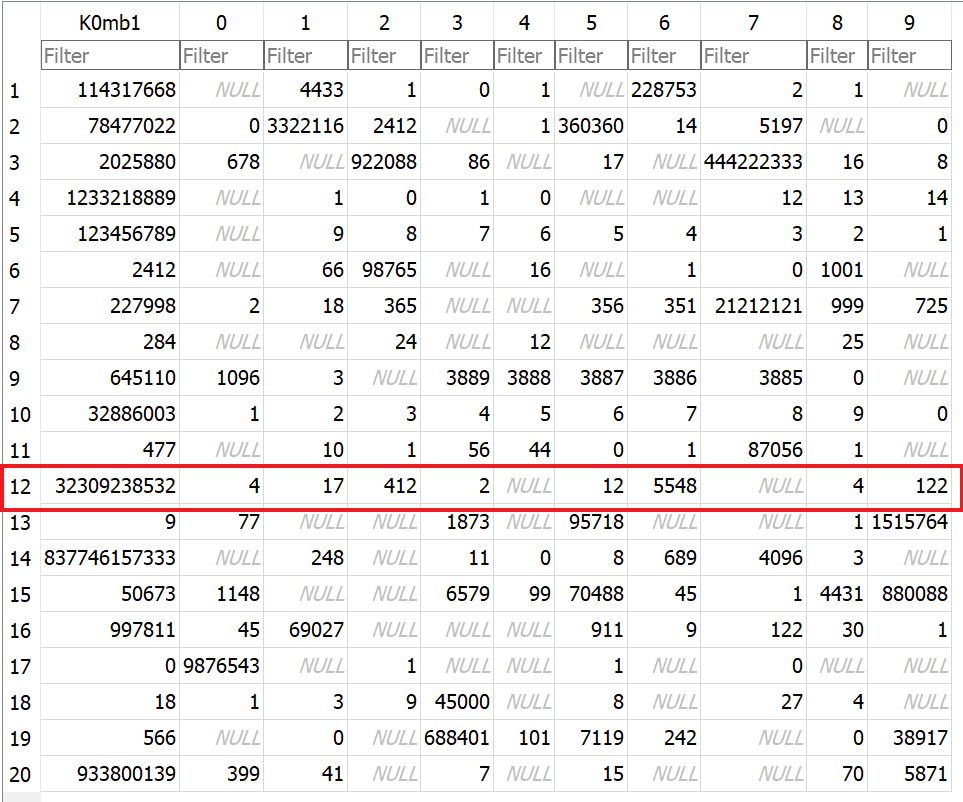
Vi fokuserer nu på denne række, da den specifikt var gemt væk - i en tabel, der også specifikt var gemt væk. Og nu skal vi bruge hintet fra tidligere: concatenate. For hvert ciffer i K0mb1 tallet (32309238532), concatenater vi den tilsvarende celle. Dette havde vi forsøgt i mange varianter med andre rækker, men med række 12 får vi nu
2 412 2 4 122 412 2 4 12 2 412
eller samlet: 24122412241224122412, altså juleaften gentaget fem gange. Dette er koden til ZIP-filen, og tekstfilen indeni indeholder flaget.
Den fiksede databasefil kan hentes her: fixed.db
B-Tree Leaf Page Parser
Følgende kode parser alle records for en B-tree leaf page. Finder den nogle BLOBs, tjekker den for PNG, JPG, og ZIP filer og gemmer med korrekt extension, ellers bare med .bin.
from Crypto.Util.number import long_to_bytes as l2b, bytes_to_long as b2l
import sys
def n2b(s):
return bin(s)[2:].zfill(8)
def varint(db, o):
s = ""
i = 0
while True:
p = n2b(db[o + i])
s += p[1:]
if p[0] == "1":
s += ""
else:
break
i += 1
return int(s, 2), i
def get_dt(b):
if b == 0:
return ("NULL", 0)
if b == 1:
return ("int8", 1)
if b == 2:
return ("int16", 2)
if b == 3:
return ("int24", 3)
if b == 4:
return ("int32", 4)
if b == 5:
return ("int48", 6)
if b == 6:
return ("int64", 8)
if b == 7:
return ("float64", 8)
if b == 8:
return ("0", 0)
if b == 9:
return ("1", 0)
if b >= 12 and b % 2 == 0:
length = (b - 12) // 2
return (f"BLOB (len {length})", length)
if b >= 13 and b % 2 == 1:
length = (b - 13) // 2
return (f"string (len {length})", length)
raise ValueError("Invalid serial type")
def parse_page(db, offset):
print(f"PARSING PAGE AT OFFSET {hex(offset)}")
print(db[offset:offset+100].hex(" "))
PAGE_SIZE = b2l(db[0x10:0x12])
noffsets = db[offset + 4]
idxs = [b2l(db[offset + 8 + i * 2:offset + 8 + (i + 1) * 2]) for i in range(noffsets)] + [PAGE_SIZE]
s_idxs = list(sorted(idxs))
for i, idx in enumerate(idxs[:-1]):
print(f"RECORD {i} AT {hex(idx)}")
o = offset + idx
o_next = offset + s_idxs[s_idxs.index(idx) + 1]
print(db[o:o_next].hex(" "))
# First three fields: length, row_id, header length (num cols + 1)
rec_len, skip = varint(db, o)
o += skip
row_id = db[o + 1]
hdr_len = db[o + 2]
# Remaining header = data types for columns
dts = []
ptr = o + 3
while ptr < o + 3 + hdr_len - 1:
dt, skip = varint(db, ptr)
dts.append(dt)
ptr += 1 + skip
# Remainder = data values
values = db[o + 3 + hdr_len - 1:o_next]
print(f" Length {rec_len}")
print(f" Row ID {row_id}")
print(f" Columns: {hdr_len - 1}")
print(f" Column data types:")
# Get data types and fetch values
val_ptr = 0
for dt in dts:
typ, val_len = get_dt(dt)
print(f" {hex(dt)}: {typ}", end="")
if val_len == 0:
print()
continue
val = values[val_ptr:val_ptr + val_len]
val_ptr += val_len
if typ.startswith("string"):
print(f" = \"{val.decode()}\"", end="")
elif typ.startswith("BLOB"):
print(f" = {val}", end="")
# Save results
if False:
ext = "png" if b"PNG" in val else "zip" if b"PK" in val else "jpg" if b"JFIF" in val else "bin"
with open(f"./blobs/BLOB-{val_ptr}.{ext}", "wb") as f:
f.write(val)
else:
print(f" = {b2l(val)} (0x{val.hex()})", end="")
print()
# Remaining unknown data?
if len(values[val_ptr:]) > 0:
print(f" REMAINING AT {hex(o_next - offset - len(values) + val_ptr)}: {values[val_ptr:].hex(' ')} ({values[val_ptr:]})")
print()
with open(sys.argv[1], "rb") as f:
db = f.read()
# Kan nemt smides i et while loop for at parse alle pages
parse_page(db, 0xa000)